Тут мне видится два этапа в распознавании изображения.
1) Предварительный (быстрый - с минимумом пикселей). Находим картинку 1 в координатах (0,0, $_xmax,$_ymax) и вычисляем точные координаты для окончательного поиска .
2) Окончательный. Находим картинку 2.
[spoiler=Картинки для поиска выделены на скриншоте.]
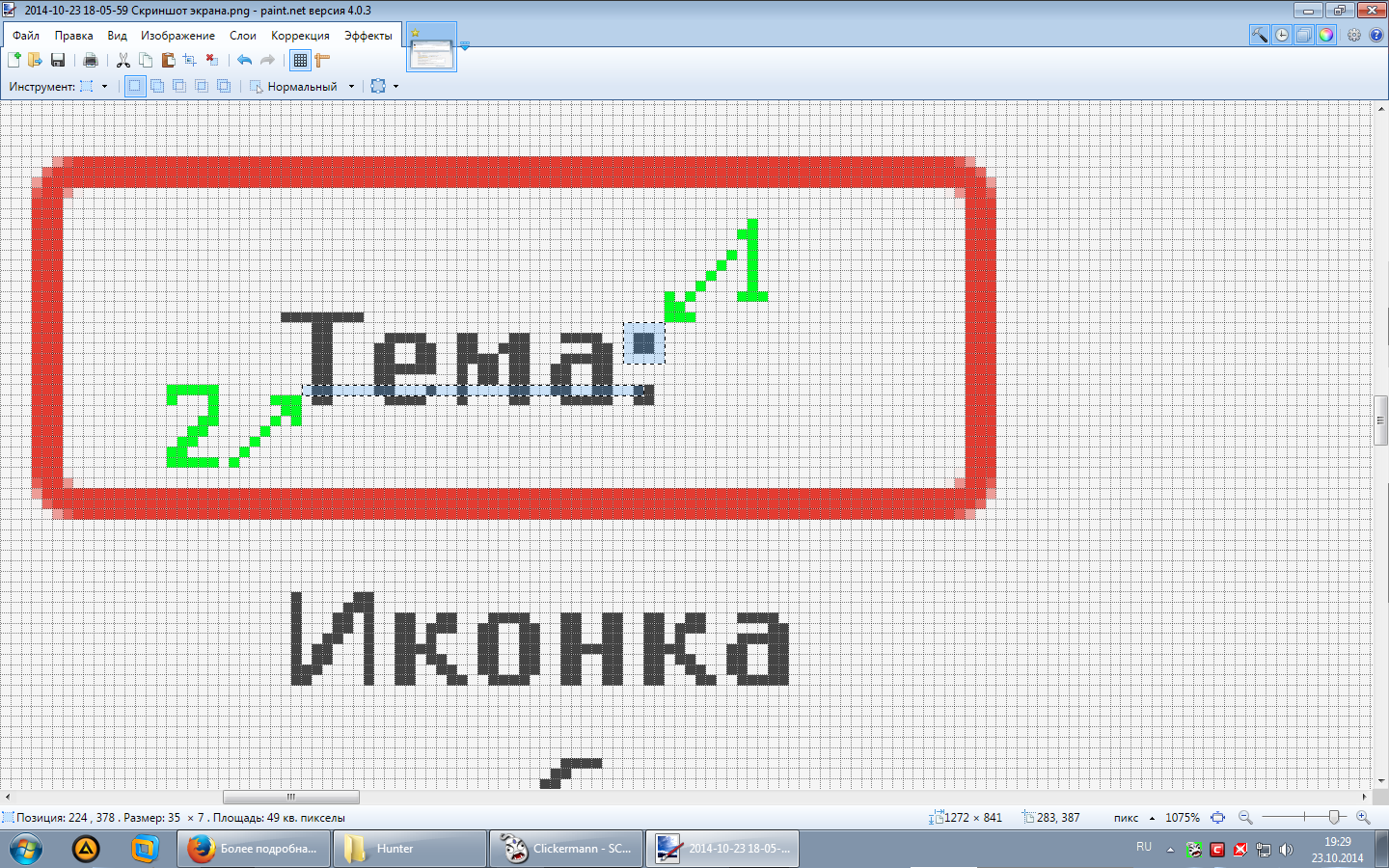
[/spoiler]
Картинку 2, наверно, можно выбрать более оптимальную. В конкретно этом примере, колормод и % совпадения не применяются.
Выигрыш в скорости предполагается получить за счет первого этапа распознавания (поиска маленького,
уникального изображения, на большой площади) и за счет того, что вторая (большая) картинка, будет распознаваться в точно указанных координатах (т.е. всего один раз за цикл распознавания).
P.S. Провёл сравнительные испытания скрипта Андрея и своего скрипта. В результате мой сценарий проиграл по времени поиска картинки примерно в 2 раза(!).  Это только на этом конкретном задании. Если же на экране было бы больше двоеточий (которые я использовал как уникальные картинки), то потери скорости были бы нереальные просто.
Это только на этом конкретном задании. Если же на экране было бы больше двоеточий (которые я использовал как уникальные картинки), то потери скорости были бы нереальные просто.
Делаю для себя вывод, что ускорить IF_PICTURE_IN используя комбинации из IF_PICTURE_IN не получится! 
Урок усвоен, спасибо, было интересно. 
P.S.P.S В поисках истины я провёл еще несколько тестов с IF_PICTURE_IN. И оказалось, что что ускорить IF_PICTURE_IN используя комбинации из IF_PICTURE_IN всё таки можно.
Ошибка моего первого теста была в том, что я взял для первого (предварительного) поиска слишком большую картинку (16 пикселей). Если же уменьшить её до 3 уникальных пикселей, то скорость поиска будет равной скорости скрипта Андрея, даже если уменьшить его картинку 01.bmp в 2 раза. Другими словами, поиск изображения в два прохода, при определенных условиях, очень даже оправдан, если удастся найти, для первого прохода, тот самый заветный уникальный пиксель, который поможет сузить зону поиска для второго окончательного поиска.


